LSTM
This seems great, but in practice RNN barely works due to exploding/vanishing gradient, which is cause by a series of multiplication of the same matrix. On the other side, it also have the problem of long-term dependencies. To solve this, we can use a variation of RNN, called long short-term memory (LSTM), which is capable of learning long-term dependencies.
sigmoid - gate function [0, 1], tanh - regular information to [-1, 1]

The sigmoid layer outputs numbers between zero and one, describing how much of each component should be let through. A value of zero means "let nothing through," while a value of one means “let everything through!”
The math behind LSTM can be pretty complicated, but intuitively LSTM introduce
input gate
output gate
forget gate
memory cell (internal state)

The cell state is kind of like a conveyor belt. It runs straight down the entire chain, with only some minor linear interactions. It's very easy for information to just flow along it unchanged.
LSTM resembles human memory: it forgets old stuff (old internal state forget gate) and learns from new input (input node input gate)

LSTMs also have this chain like structure, but the repeating module has a different structure. Instead of having a single neural network layer, there are four, interacting in a very special way.
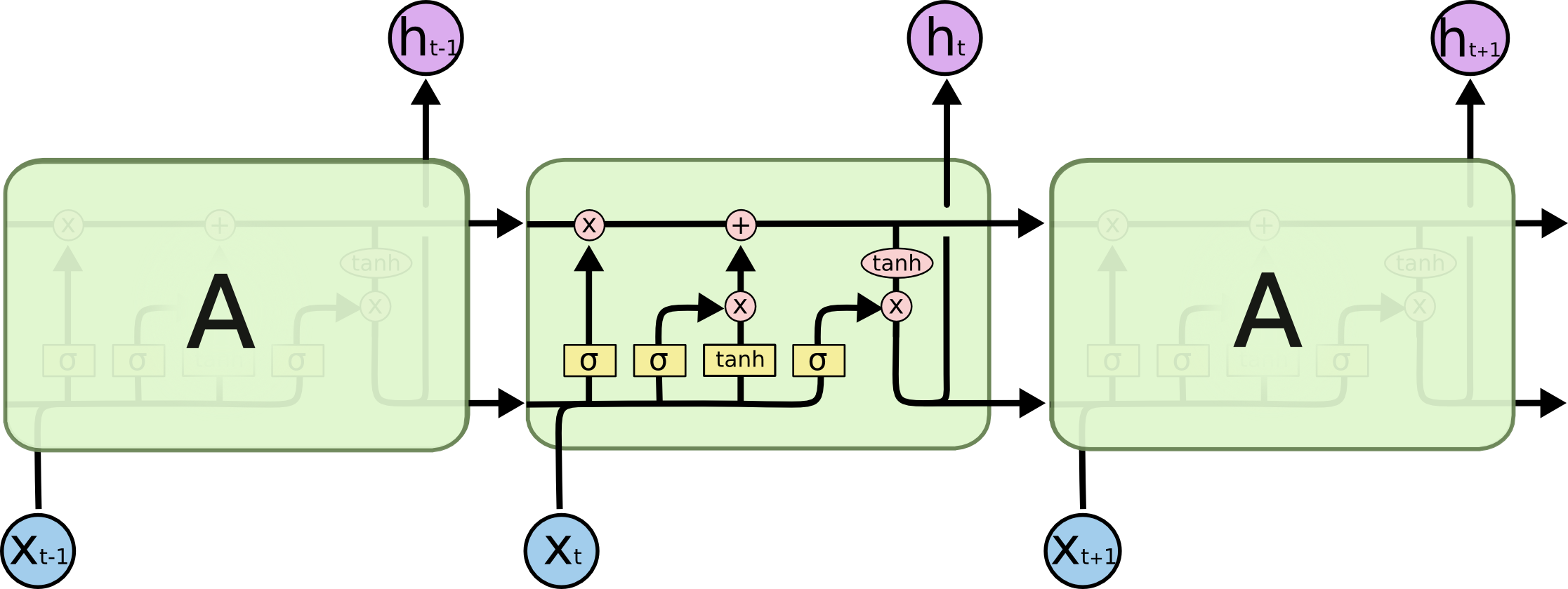
Step-by-Step LSTM Walk Through

At first, we apply Forget gate: ft=σ(Wf⋅[ht−1,xt]+bf), caculate what information we should forget for previous information

The next step is to decide what new information we're going to store in the cell state.
Input gate: it=σ(Wi⋅[ht−1,xt]+bi), a sigmoid layer decides which values we’ll update.
A tanh layer creates a vector of new candidate values: Ct~=tanh(Wc⋅[ht−1,xt]+bc), that could be added to the state.

Then we update Memory cell C: Ct=ft∗Ct−1+it∗Ct~,
We multiply the old state by ft, forgetting the things we decided to forget earlier. Then we add it∗Ct~. This is the new candidate values, scaled by how much we decided to update each state value.

This output will be based on our cell state, but will be a filtered version.
First, we run a Output gate: ot=σ(Wo⋅[ht−1,xt]+bo), which decides what parts of the cell state we’re going to output, .
Then, we put the cell state through tanh (to push the values to be between [−1,1] ) and multiply it by the output of the sigmoid gate, so that we only output the parts we decided to: ht=tanh(Ct)∗ot
Why solve vanishing gradient?
Details from here
The additive update function for the cell state gives a derivative thats much more ‘well behaved’
The gating functions allow the network to decide how much the gradient vanishes, and can take on different values at each time step. The values that they take on are learned functions of the current input and hidden state.
(Optional) Implementation
LSTM for IMDB review
Shapes
The output shape of the Embedding layer is (?, 500, 32).
Ct: (?, 100)
ht: (?, 100)
The calculation for forget gate ft=σ(Wf⋅[ht−1,xt]+bf) is composed of:
Summary
LSTM uses a "conveyor belt" to get longer memory than SimpleRNN.
Each of the following blocks has a parameter matrix:
Forget gate.
Input gate.
New values.
Output gate.
Number of parameters:
4×shape(h)×[shape(h)+shape(x)]
Last updated